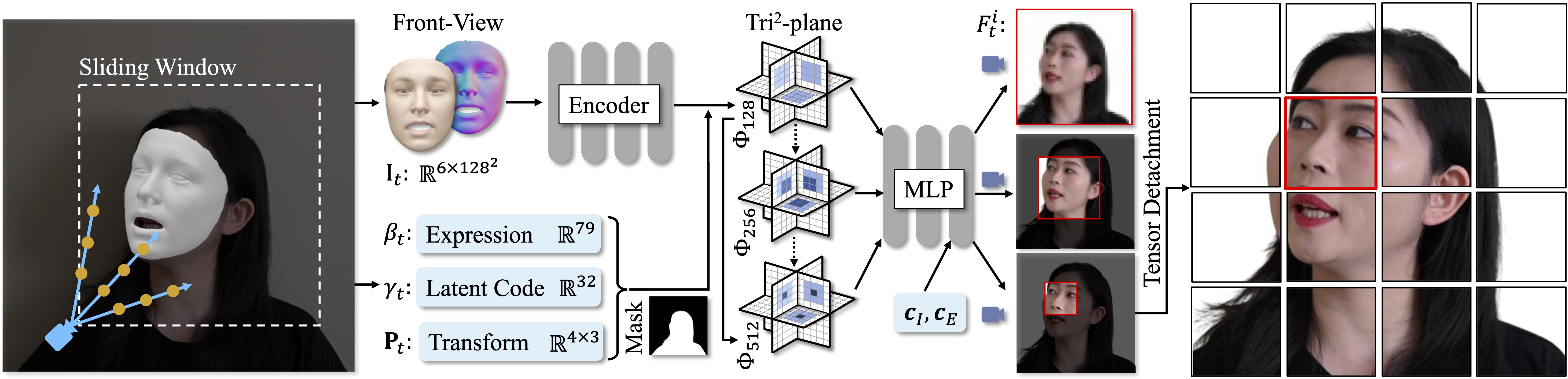
Recent years have witnessed considerable achievements in facial avatar reconstruction with neural volume rendering. Despite notable advancements, the reconstruction of complex and dynamic head movements from monocular videos still suffers from capturing and restoring fine-grained details. In this work, we propose a novel approach, named Tri2-plane, for monocular photo-realistic volumetric head avatar reconstructions. Distinct from the existing works that rely on a single tri-plane deformation field for dynamic facial modeling, the proposed Tri2-plane leverages the principle of feature pyramids and three top-to-down lateral connections tri-planes for details improvement. It samples and renders facial details at multiple scales, transitioning from the entire face to specific local regions and then to even more refined sub-regions. Moreover, we incorporate a camera-based geometry-aware sliding window method as an augmentation in training, which improves the robustness beyond the canonical space, with a particular improvement in cross-identity generation capabilities. Experimental outcomes indicate that the Tri2-plane not only surpasses existing methodologies but also achieves superior performance across quantitative and qualitative assessments.