Let us use the prompt: "Turn him/her into Siggraph style" to have a look!
↓ The appearance have a sense of technology with smooth skin and blue eyes ↓
"Turn her into Siggraph style !"
"Turn him into Siggraph style !"
"Turn him into Siggraph style !"
Source Drive Actor
Gallery
"Turn him into Dr. Manhattan."
"Turn him into Dragon Ball comic style."
"Turn him into the Hulk."
"Turn him into the Joker."
"Turn him into Pixar style."
"Turn him into cartoon style."
"Turn him into Shrek."
"Turn him into Pixar style."
"Turn him into pixar style, as in Toy Story."
"The white walker, as in Game of Thrones."
"Turn him as Hulk in Marvel."
"Turn him looks like Kobe Bryant."
"Turn her into Elsa, in Frozen (Disney movie)."
"Turn him into the Dragon Ball comic style."
"Turn her into cartoon style."
"Turn her into Van Gogh."
"Turn her looks like panda."
"The Hulk, as in Marvel Universe."
"The Joker, as in DC film."
"Turn her look like a cute baby."
Abstract
We propose TextToon, a method to generate a drivable toonified avatar. Given a short monocular video sequence and a written instruction about the avatar style, our model can generate a high-fidelity toonified avatar that can be driven in real-time by another video with arbitrary identities. Existing related works heavily rely on multi-view modeling to recover geometry via texture embeddings, presented in a static manner, leading to control limitations. The multi-view video input also makes it difficult to deploy these models in real-world applications. To address these issues, we adopt a conditional embedding Tri-plane to learn realistic and stylized facial representations in a Gaussian deformation field. Additionally, we expand the stylization capabilities of 3D Gaussian Splatting by introducing an adaptive pixel-translation neural network and leveraging patch-aware contrastive learning to achieve high-quality images. To push our work into consumer applications, we develop a real-time system that can operate at 48 FPS on a GPU machine and 15-18 FPS on a mobile machine. Extensive experiments demonstrate the efficacy of our approach in generating textual avatars over existing methods in terms of quality and real-time animation.
Method
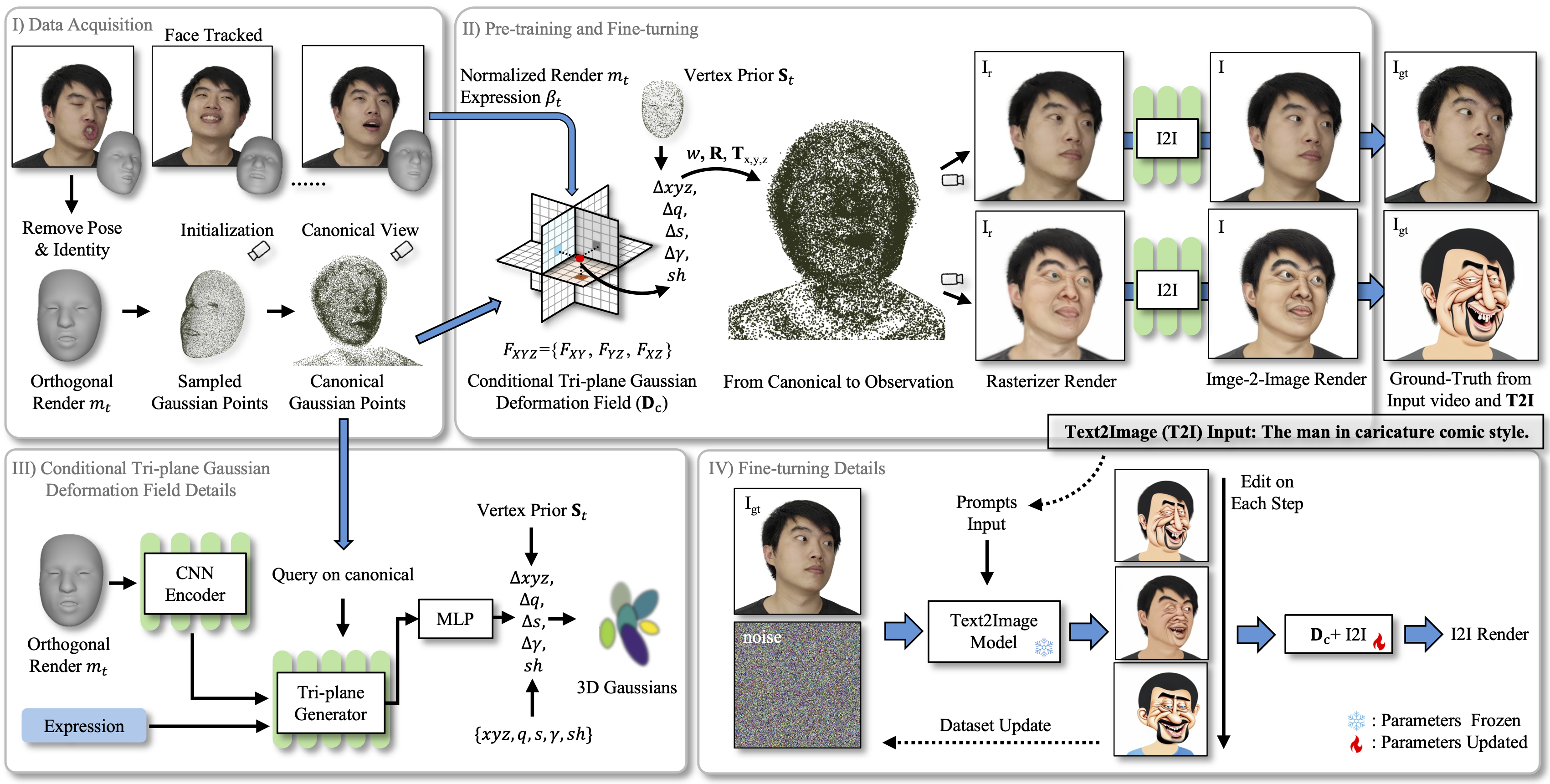
Figure. 2. The overview of our methods. It takes a single video as input and tracked on each frames, then initialize the canonical Gaussian point clouds through the tracked geometry of the first frame. We leverage the rigid transformation matrix (R, Tx,y,z) and a learnable lazy factor w to transfer points from the canonical space to the observation space. The proposed conditional Tri-plane Gaussian Deformation Field Dc takes the normalized render map mt, expression βt and vertex position St to predict the Gaussian properties deformation on each points. The pre-training and fine-tuning share the same structure, but the targets are realism appearance and T2I synthesized appearance respectively. The details of conditional Tri-plane Gaussian Deformation Field and Text2Image editing are shown in III) and IV) respectively.
Demo Video
[No voice and audio in the Demo Video]
Real-Time Demo
We present a real-time demo on Apple Macbook Pro (M1 Chip)
Multi-View Results [from monocular input]
We present multi-view results learned from monocular inputs in various styles and facial expressions, demonstrating our method's capacity to recover multiple views from single-view input. The input of second line comes from Yufeng's demo video.
Animation
We can re-animate the artistic avatar by different prompts under cross-identity reenactment (the last row is the cross-identity on pre-trained appearance).
Reading Materials
We have listed some questions that you may concern when reading this paper.
1.: Why not include the Next3D, Deformtoon3D in the baselines?
A.1: The DeformToon3D and Next3D requires extra facial alignment and depend on StyleGAN inversion for specific identities. And DeformToon3D is built based on StyleSDF. The StyleSDF does not seem to have an inversion method so far, please refer to this issue for more details. In addition, we provide some comparison results with Next3D by PTI inversion in the video, but for the sake of rigor, they are not included in the main paper. Please refer to Video.Q.1 for more details (another sample is provided in demo video 05:04-05:26).
Video.A.1. In comparison with Next3D, PTI (StyleGAN inversion) results in facial identity drift. Furthermore, the two styles associated with Next3D (Pixar and Cartoon) are not distinct.
2: Misalignment of gaze control or other complex expressions?
A.2: We do not include complex facial movements for two reasons: (1) The face edited by Text2Image does not include gaze control and complex expressions. In fact, such movements are rarely found in real-world animations, such as Detective Conan. (2) To ensure pipeline inference efficiency, particularly 3DMM tracking efficiency, the 3DMM algorithm we use does not include eye tracking, as Figure. 4 in below. Additionally, please incorporate baseline methods into comparisons when evaluation.
Figure. 3. Visualization of the 3DMM model we used, which does not contain eyeballs annotations.
3: What is the structure of generator and encoder?
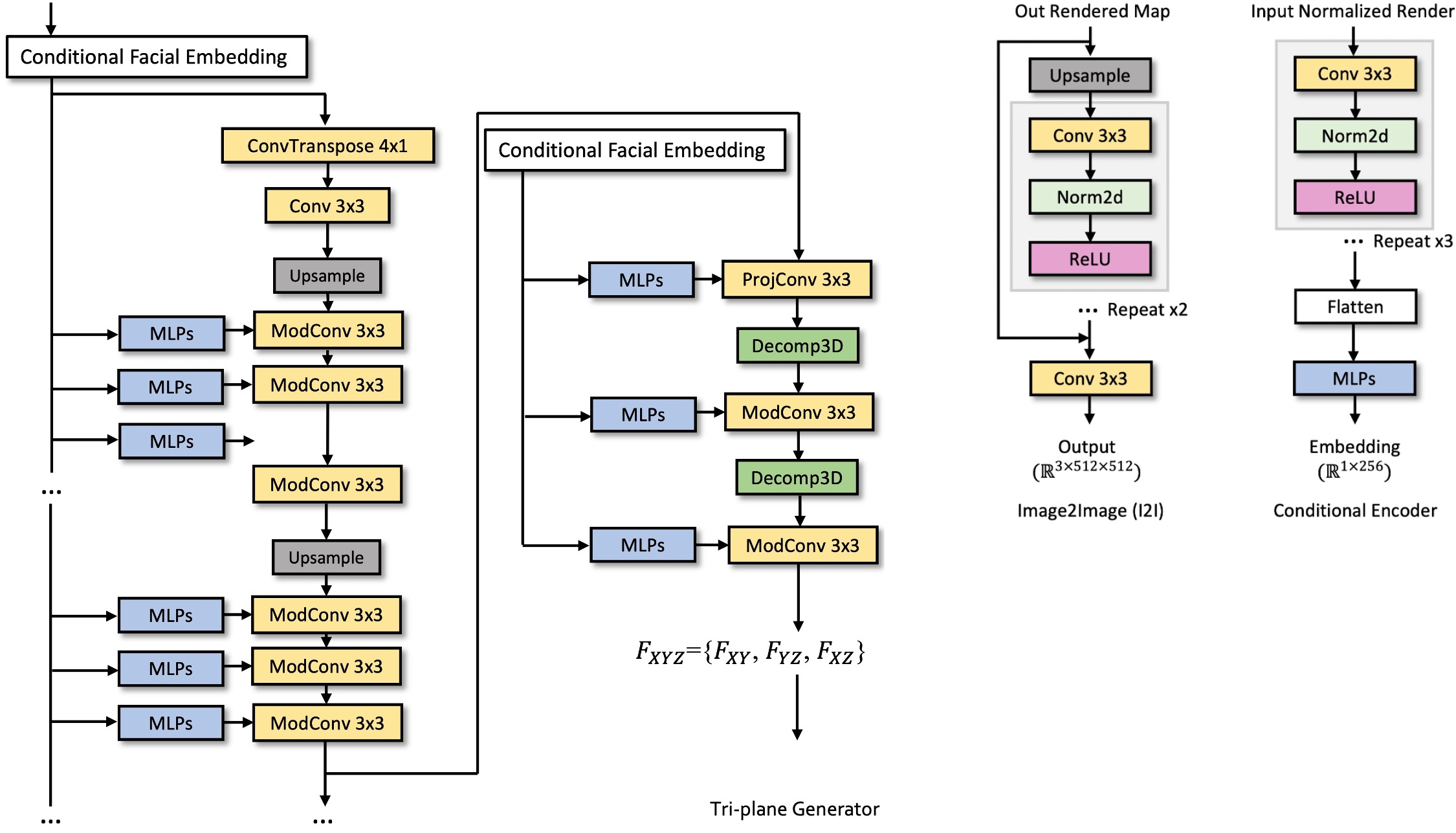
A.3: The generator and encoder are composed of some convolution and MLP layers. The overall weight of the model is about 49Mb with each components. The detail of Tri-plane generator, image2image translation module (I2I) and conditional input encoder are shown in Figure 5.
Figure. 4. The detail of each components. The conditional facial embedding is a concatenation of encoded orthogonal rendering and the corresponding 3DMM expression coefficients. The size of out rendered map for I2I input is 32 × 512 × 512 and the output size is 3 × 512 × 512. The size of input normalized render is 3 × 128 × 128, and the output of the conditional encoder (embedding) is 1 × 256.
We gratefully acknowledge the research data provided by these methods.
BibTeX
@article{song2024texttoon,
title={TextToon: Real-Time Text Toonify Head Avatar from Single Video},
author={Song, Luchuan and Chen, Lele and Liu, Celong and Liu, Pinxin and Xu, Chenliang},
journal={arXiv preprint arXiv:2410.07160},
year={2024}
}