StreamME: Simplify 3D Gaussian Avatar within Live Stream
ACM Siggraph 2025
Luchuan Song1,2, Yang Zhou2, Zhan Xu2, Yi Zhou2,Deepali Aneja2, Chenliang Xu1
1University of Rochester, 2Adobe Research
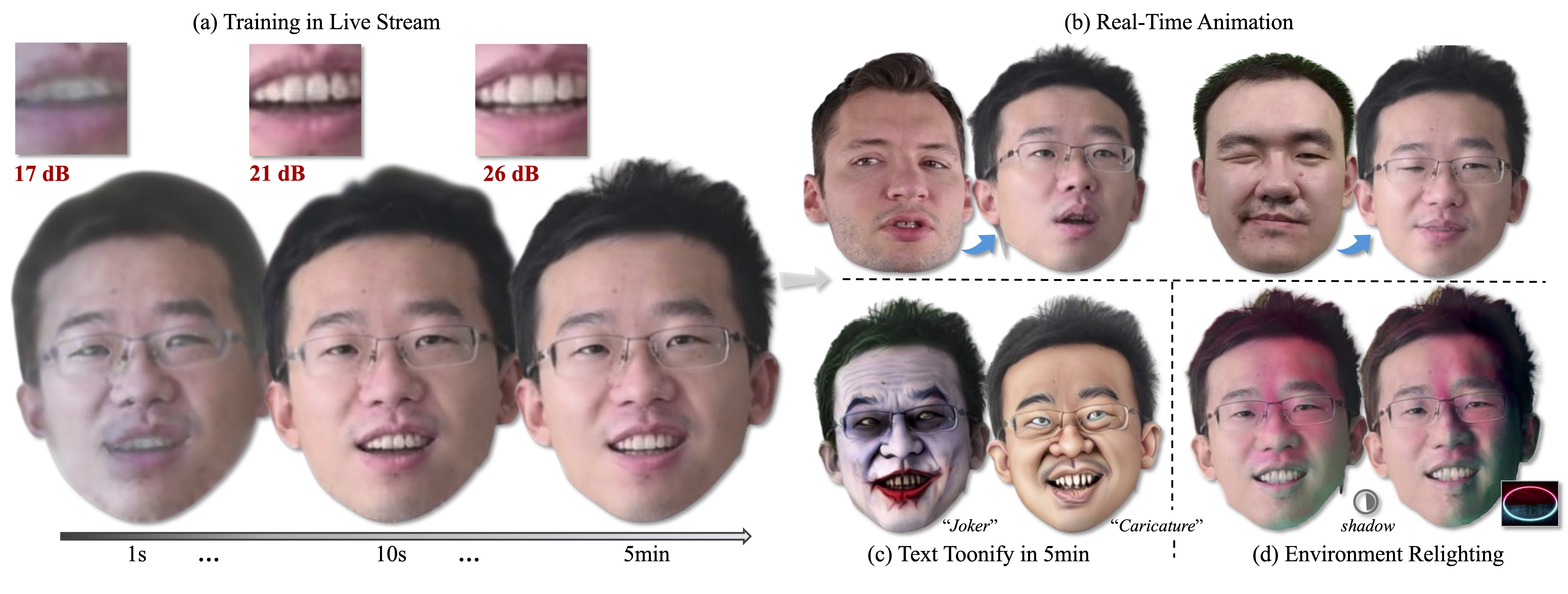
Figure 1. The StreamME takes live stream (or monocular) video as input to enable rapid 3D head avatar reconstruction. It achieves impressive speed, capturing the basic facial appearance within 10 seconds (PSNR = 21 dB) and reaching high-quality fidelity (PSNR = 26 dB) within 5 minutes, as shown in (a). Notably, StreamME reconstructs facial features through on-the-fly training, allowing simultaneous recording and modeling without the need for pre-cached data (e.g. pre-training model). Additionally, StreamME facilitates real-time animation in (b), toonify in (c) and relighting in (d) (the background light image is shown in bottom right and we move the light position to create shadows on face) from the 5-minute reconstructed appearance, supporting the applications in VR and online conference. Natural face©Xuan Gao et al. (CC BY), and ©Wojciech Zielonka et al. (CC BY).
On-The-FLY Reconstruction [Training in Stream]
Left is the ground-truth, Right is the reconstruction appearacne.
The input are sampled frame-by-frame from video
[The slight stroboscopic noise on the face is because each frame is being trained and iterated parameters]
Real-Time Reconstruction/Reenactment within Live-Stream
The input are sampled frame-by-frame from video
[The slight stroboscopic noise on the face is because each frame is being trained and iterated parameters]
Abstract
We propose StreamME, a method focuses on ultra-fast 3D avatar reconstruction. The StreamME synchronously records and reconstructs a head avatar from live video streams without any pre-cached data, enabling seamless integration of the reconstructed appearance into downstream applications. This exceptionally fast training strategy, which we refer to as on-the-fly training, is central to our approach. Our method is built upon 3D Gaussian Splatting (3DGS), eliminating the reliance on MLPs in deformable 3DGS and relying solely on geometry, which significantly improves the adaptation speed to facial expression motion. To further ensure high efficiency in on-the-fly training, we introduced a simplification strategy based on primary points, which distributes the point clouds more sparsely across the facial surface, optimizing points number while maintaining rendering quality. Leveraging the on-the-fly training capabilities, our method protects the facial privacy and reduces communication bandwidth in VR system or online conference. Additionally, it can be directly applied to downstream appliaction such as animation, toonify, and relighting.
Overview
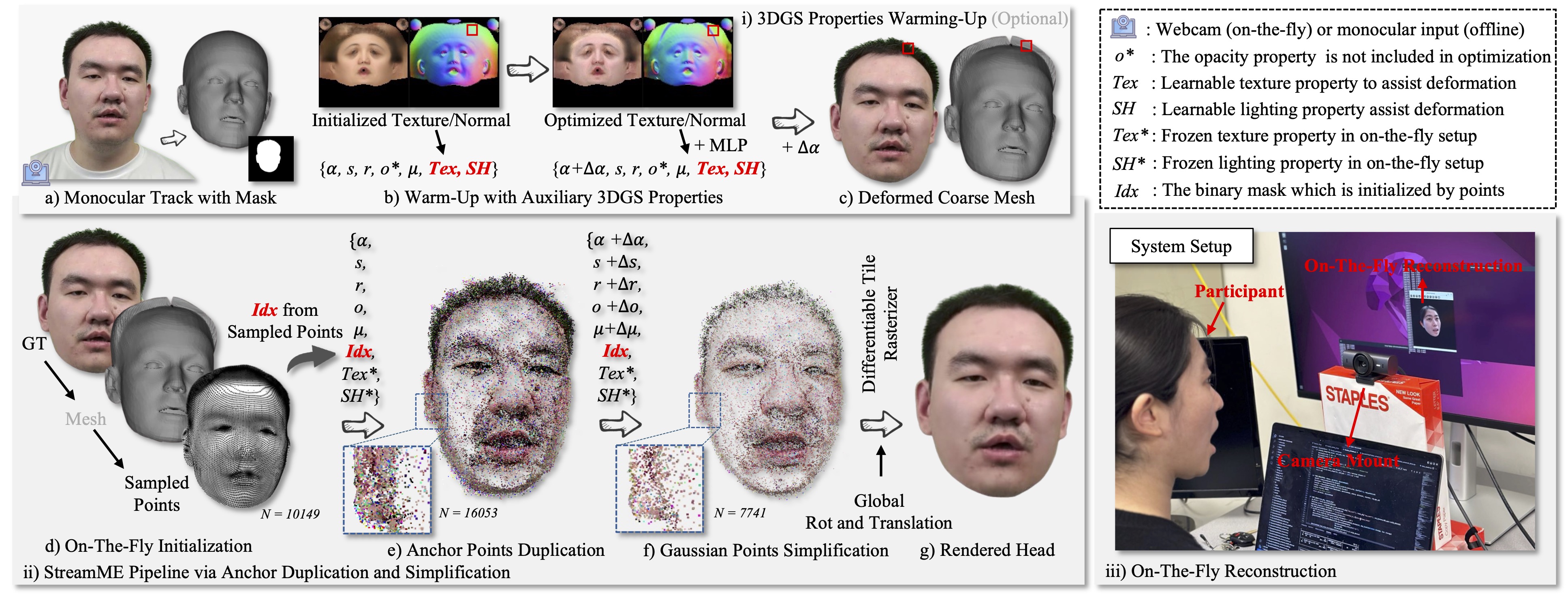
Figure 2. The overview the pipeline of StreamME. We list three components at here. i) The 3DGS Properties Warming-Up (Optional): we introduce two auxiliary learnable 3D Gaussian attribute texture and illumination, refining the UV vertex positions to improve facial geometry detail (e.g. here, we show the coarse displacement for the vertices around the hair). This step is optional, and the users may also opt to use the tracked head without displacement. ii) Anchor Duplication and Simplification: we freeze the Tex and SH attributes and introduce a binary learnable mask, initialized with all values set to 1, from the UV vertices sampled on the mesh. Natural face©Xuan Gao et al. (CC BY).

Figure 3. We employ the proposed Idx for anchor binding, elimination the motion irrelevant points and simplification the over-small size/opacity points to reduce computational overhead. (a) The anchor points are sampled from the mesh and multiple duplicated for detail representation. (b) The motion-aware Idx tends to remove points, as there are none motion gradients around the forehead in canonical space. (c) The learnable masks from Idx for deleting the small size and opacity points within training. Please zoom-in for details. Natural face©Xuan Gao et al. (CC BY).
Demo Video
[The demo video for StreamME, which contains subtitles and dubbing. Please turn up the volume for better experience]Applications
[We apply different text prompts for texture editing. The algorithm comes from TextToon]
[We apply the offset to the geometry, with the original tracked head displayed in the middle as reference]
[Eyeball Animation]
Point Cloud Visualization
[We use MeshLab at here for visualization]
From left to right: without Idx and Simplification, only with Idx, and with both Idx and Simplification.
BibTex
@article{song2025Stream,
title={StreamME: Simplify 3D Gaussian Avatar within Live Stream},
author={Luchuan Song, Yang Zhou, ZHan Xu, Yi Zhou, Deepali Aneja, Chenliang Xu},
journal={SIGGRAPH},
year={2025},
publisher={ACM New York, NY, USA}
}
Our website template comes from ProxyCap and is modified based on it. Thanks to the authors for providing beautiful icons.